Python은 인터넷에서 정보를 가져오기 위한 다양한 패키지들을 제공하고 있습니다. 이 중에서 requests 라이브러리는 HTTP 요청을 보내고 받을 수 있는 기능을 제공하여 웹 크롤링, API 호출 및 웹 서비스와의 상호작용에 주로 사용됩니다. 이번 글에서는 python requests 정리 및 네이버 뉴스 크롤링 예제 까지 공부해보겠습니다.
[목차]
1. Python requests 라이브러리란?
2. Python requests 주요 기능
3. Python requests 예제 - 네이버 뉴스 크롤링
4. 결론 및 의견
1. Python requests 라이브러리란?
requests 라이브러리는 인터넷에서 데이터를 가져오기 위한 Python 패키지 중 하나입니다. HTTP 요청을 보내고 받을 수 있는 기능을 제공하며, 다양한 기능들을 제공합니다. requests 라이브러리는 Python 2.7, 3.4 이상의 버전에서 사용 가능합니다.
2. Python requests 주요 기능
GET 요청
requests.get() 메서드를 사용하여 GET 요청을 보낼 수 있습니다. GET 요청은 URL을 통해 데이터를 요청하고 응답으로 받아옵니다. 다음은 GET 요청 예제입니다.
|
1
2
3
4
5
|
import requests
response = requests.get('https://jsonplaceholder.typicode.com/posts/1')
print(response.json())
|
cs |
이 코드는 requests 패키지의 get() 메서드를 사용하여 https://jsonplaceholder.typicode.com/posts/1 URL에 GET 요청을 보내고, 이에 대한 응답으로 받은 데이터를 JSON 형식으로 출력합니다.
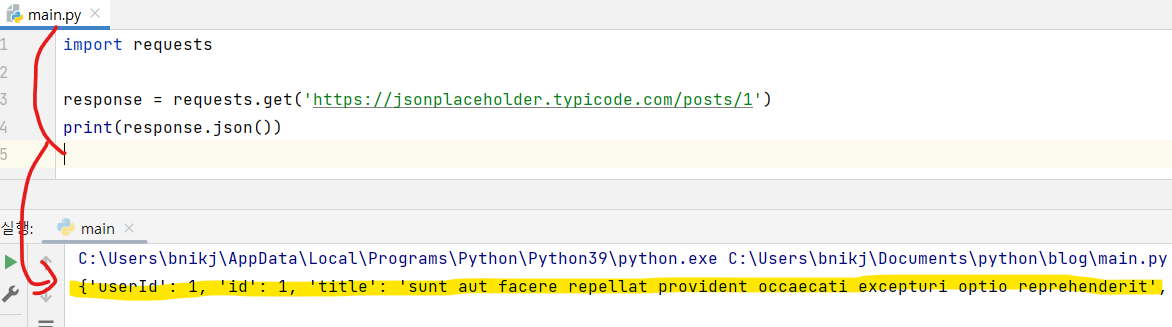
|
|
{'userId': 1, 'id': 1, 'title': 'sunt aut facere repellat provident occaecati excepturi optio reprehenderit'} |
cs |
POST 요청
requests.post() 메서드를 사용하여 POST 요청을 보낼 수 있습니다. POST 요청은 URL을 통해 데이터를 전송하고 응답으로 받아옵니다. 예를 들어, 다음은 POST 요청 예제입니다.
|
1
2
3
4
5
6
|
import requests
data = {'title': 'foo', 'body': 'bar', 'userId': 1}
response = requests.post('https://jsonplaceholder.typicode.com/posts', data=data)
print(response.json())
|
cs |
예제에서는 requests 패키지의 post() 메서드를 사용하여 https://jsonplaceholder.typicode.com/posts URL에 POST 요청을 보내고, 이에 대한 응답으로 받은 데이터를 JSON 형식으로 출력합니다.
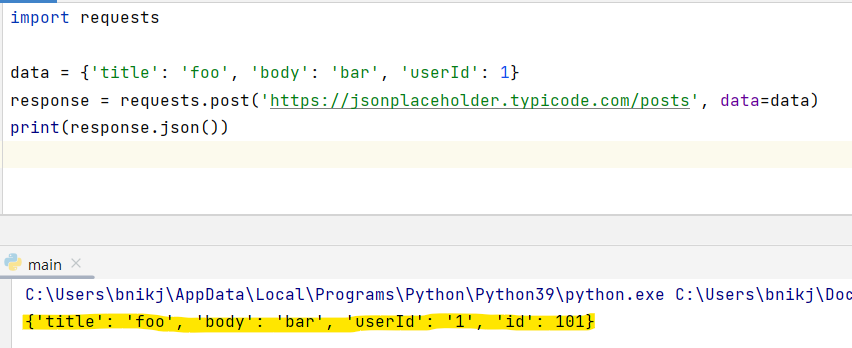
인증
requests 패키지를 사용하여 HTTP 인증을 처리할 수 있습니다. 인증은 requests.get() 또는 requests.post() 메서드 호출 시 auth 매개 변수를 사용하여 처리할 수 있습니다. 예를 들어, 다음은 인증 예제입니다. 이 코드는 실제로 user와 pass를 입력해야 구현이 되며, 코드 구현 방식으로 참고하시면 됩니다.
|
1
2
3
4
5
|
import requests
response = requests.get('https://api.github.com/user', auth=('user', 'pass'))
print(response.status_code)
|
cs |
requests 패키지의 get() 메서드를 사용하여 https://api.github.com/user URL에 GET 요청을 보내고, 이에 대한 응답으로 받은 데이터를 출력합니다. 이때 auth 매개 변수를 사용하여 인증을 처리합니다.
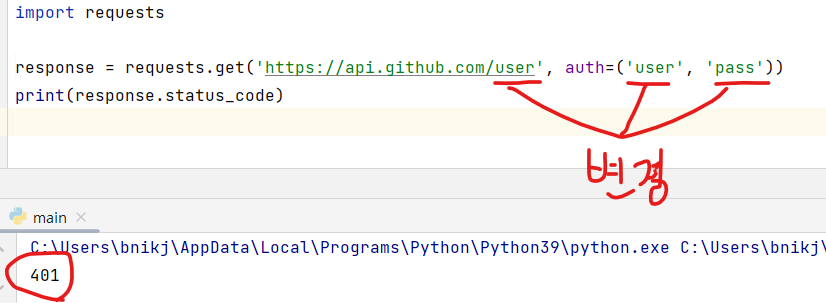
user와 pass 정보 설정을 안했기 때문에 401 응답을 받게 됩니다. 이는 요청한 리소스에 대해 인증정보가 없어서 자격이 없다고 생각하시면 됩니다. 실제로 인증정보가 확인되면 200 응답을 받게 됩니다.
에러 처리
requests 패키지는 HTTP 요청 중 발생할 수 있는 다양한 에러들을 처리할 수 있습니다. 예를 들어, 다음은 404 에러를 처리하는 예제입니다.
|
1
2
3
4
5
6
|
import requests
response = requests.get('https://jsonplaceholder.typicode.com/invalid_url')
if response.status_code == 404:
print('Not Found')
|
cs |
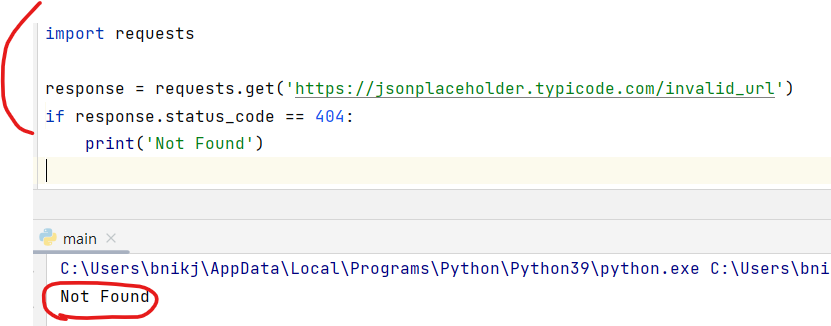
이 코드에서는 requests 패키지의 get() 메서드를 사용하여 https://jsonplaceholder.typicode.com/invalid_url URL에 GET 요청을 보내고, 이에 대한 응답으로 받은 상태 코드를 확인하여 404 에러가 발생한 경우 "Not Found"를 출력합니다.
쿠키
requests 패키지를 사용하여 쿠키를 처리할 수 있습니다. 쿠키는 requests.get() 또는 requests.post() 메서드 호출 시 cookies 매개 변수를 사용하여 처리할 수 있습니다. 예를 들어, 다음은 쿠키 예제입니다.
|
1
2
3
4
5
|
import requests
response = requests.get('<https://httpbin.org/cookies>', cookies={'name': 'value'})
print(response.json())
|
cs |
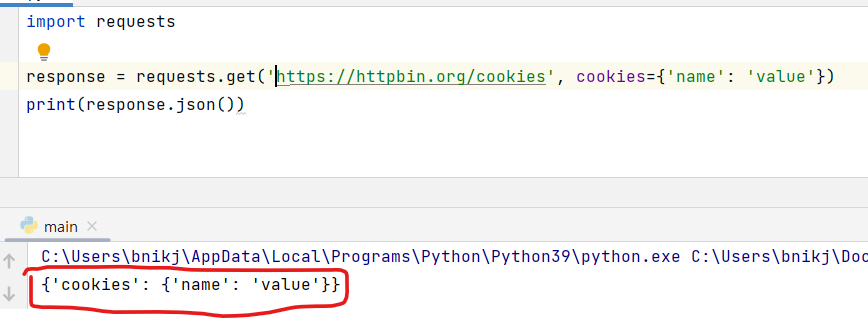
requests 패키지의 get() 메서드를 사용하여 https://httpbin.org/cookies URL에 GET 요청을 보내고, 이에 대한 응답으로 받은 쿠키 데이터를 JSON 형식으로 출력합니다.
3. Python requests 예제1 - 네이버 실시간 검색어
requests 패키지를 사용하여 네이버 실시간 검색어를 가져오는 예제입니다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
import requests
from bs4 import BeautifulSoup
# URL of the Naver News page you want to crawl
url = 'https://news.naver.com/'
# Send a GET request to the URL
response = requests.get(url)
# Check if the request was successful (status code 200)
if response.status_code == 200:
# Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(response.content, 'html.parser')
# print(soup)
# Find the news headlines
headlines = soup.select('.cjs_dept_desc')
# Print the headlines
for headline in headlines:
print(headline.text.strip())
else:
# Print an error message if the request was not successful
print(f"Request failed with status code {response.status_code}")
|
cs |
이 코드는 requests 및 BeautifulSoup 라이브러리를 가져옵니다. 그런 다음 크롤링하려는 네이버 뉴스 페이지의 URL을 정의합니다. requests.get()을 사용하여 해당 URL에 GET 요청을 보냅니다. 그런 다음 응답의 상태 코드를 확인하여 요청이 성공했는지 확인합니다(상태 코드 200).
요청이 성공하면 응답 콘텐츠가 포함된 BeautifulSoup 개체를 만들고 구문 분석기를 'html.parser'로 지정하여 BeautifulSoup을 사용하여 HTML 콘텐츠를 구문 분석합니다.
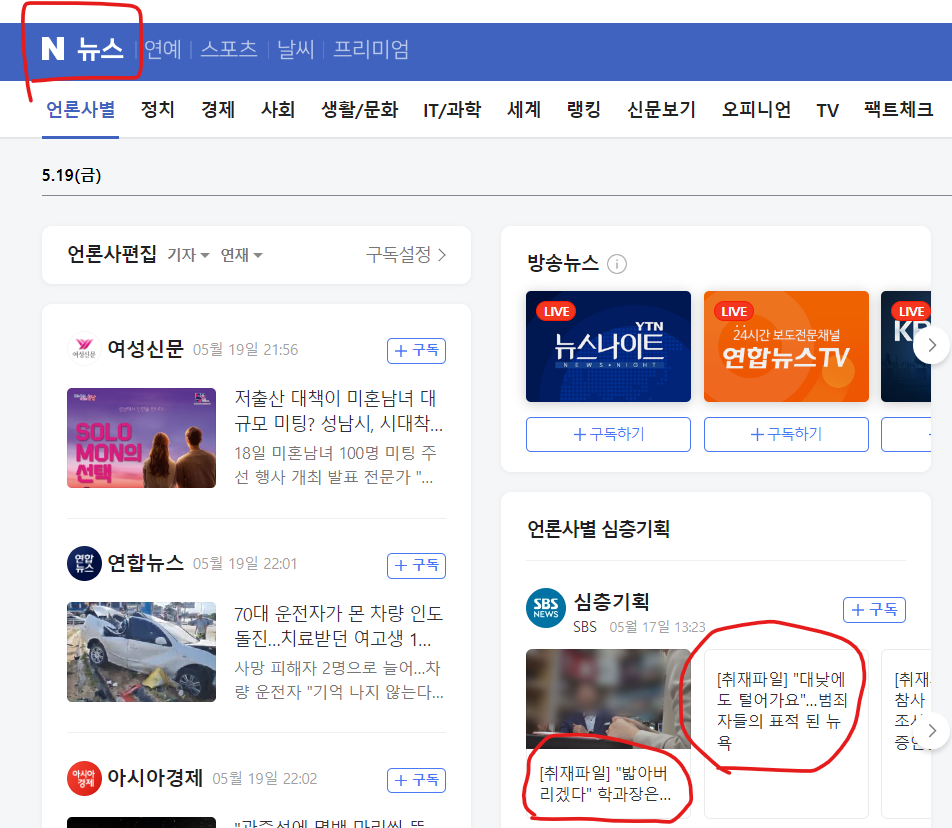
다음으로 select() 메서드를 사용하여 페이지에서 뉴스 헤드라인을 찾습니다. 이 예에서는 네이버 뉴스 페이지의 주요 헤드라인을 나타내는 'cjs_dept_desc' 클래스로 요소를 타겟팅합니다.
마지막으로 헤드라인을 반복하고 선행 또는 후행 공백을 제거한 후 각 헤드라인의 텍스트를 인쇄합니다.

4. 결론 및 의견
requests 는 HTTP 요청을 보내고 받을 수 있으며, GET 요청, POST 요청, 인증, 에러 처리, 쿠키 처리 등 다양한 기능을 제공합니다. 이러한 기능들을 활용하여 인터넷에서 데이터를 쉽게 가져올 수 있습니다. 네이버 뉴스 크롤링과 같이 쉽게 필요한 데이터를 가져 올 수 있고, 더 확장해서 게시판 자동 글쓰기, 자동 댓글달기와 같이 사무자동화 까지 응용해서 프로그램을 개발 할 수 있습니다.
[관련글]
파이썬 기초 미리보기
파이썬 기초 및 전체적으로 내용을 글로 미리보기 해보겠습니다. 파이썬은 현재 가장 인기 있는 프로그래밍 언어 중 하나입니다. 이 언어는 다양한 분야에서 활용되며, 데이터 분석, 인공지능,
2toy.net
챗GPT 란? (CHAT GPT 사용)
챗GPT 란 무엇일까요? 요즘 너무 핫하다 못해 마치 옆에 있는 선생님처럼 느껴지는 이 인공지능 AI에 대해서 이해하기 쉽게 정리하려 합니다. 결론적으로 챗GPT에게 질문을 하면, 형식적인 답이 아
2toy.net
'파이썬 (pythoon)' 카테고리의 다른 글
| Python Tkinter Canvas 사용법 및 예제 (0) | 2023.05.22 |
|---|---|
| python tkinter photoimage 사진 이미지 넣는 방법 (0) | 2023.05.21 |
| 파이썬 tkinter optionmenu - 드롭다운 메뉴 (0) | 2023.05.19 |
| Python Tkinter RadioButton - 라디오버튼 (0) | 2023.05.18 |
| 파이썬 tkinter OptionMenu - 옵션메뉴 (0) | 2023.05.17 |